


Beth yw Technolegau Iaith?
Technoleg iaith yw unrhyw fath o dechnoleg sy’n galluogi cyfrifiaduron i gyflawni tasgau ieithyddol cymhleth megis:
- gwirio a chywiro gwallau iaith
- dadansoddi testun er mwyn echdynnu gwybodaeth fel enwau, cysyniadau, teimladau a bwriad
- cynhyrchu testun
- cyfieithu
- siarad
- trawsgrifio
Digon amrwd oedd safon y technegau cyfrifiadurol cynnar a’u gallu i drin iaith. Erbyn hyn, fodd bynnag, mae technolegau iaith yn ddigon effeithiol i’w cynnwys yn llwyddiannus yn llawer o’r cynnyrch digidol rydym yn eu defnyddio bob dydd.
Gan fod technolegau iaith yn cyfuno gwybodaeth ieithyddol gyda ddulliau cyfrifiadurol, mae’n pwnc amlddisgyblaethol sydd yn dwyn ieithyddiaeth a chyfrifiadureg ynghyd, a hefyd yn goferu i feysydd eraill ble mae iaith a thechnoleg yn berthnasol, fel meysydd addysg, astudiaethau meddygol, seicoleg, cymdeithaseg a pheirianneg.
Dyma enghreifftiau amlwg lle defnyddir technolegau iaith heddiw :
Enghraifft 1 – Cynorthwyydd personol digidol
Mae teclynnau fel Amazon Alexa, Apple Siri a Google Home yn boblogaidd iawn erbyn hyn. Maen nhw’n caniatáu i ni roi gorchmynion iddynt ar lafar mewn iaith a chael ymateb priodol. Gallwn holi cwestiynau iddynt a derbyn atebion deallus a pherthnasol yn ôl ar lafar mewn iaith naturiol. Os edrychir ar y rhain yn eu cyd-destun hanesyddol ehangach, mae’r teclynnau yn cynrychioli’r cam nesaf naturiol yn natblygiad y rhyngweithio rhwng pobl a chyfrifiaduron; o’r bysellfwrdd, i’r llygoden, i gyffwrdd, i leferydd ac i sgwrsio gyda iaith naturiol.
Mae’r rhyngwynebau lleferydd deallus i gyd yn gweithredu’n debyg iawn i’w gilydd ac yn defnyddio sawl cydran technolegau iaith mewn trefn debyg i’r canlynol:
- Mae’r defnyddiwr yn siarad yn naturiol gyda’r ddyfais neu’r cyfrifiadur.
- Mae technoleg iaith adnabod lleferydd(speech recognition) yn cipio’r sain ac yn ei drosi i destun
- Mae’r testun yn cael ei drosglwyddo i gydran sy’n cyflawni prosesu iaith naturiol(natural language processing / ‘NLP’) sydd yn ceisio adnabod beth yw’r bwriad neu’r dymuniad o fewn y testun – parsio bwriad(intent parsing) – er mwyn canfod y paramedrau perthasol i’w defnyddio wrth alw’r gwasanaeth ar-lein.
- Ar ôl derbyn ymateb gan y gwasanaeth ar-lein ar ffurf data amrwd, mae meddalwedd y cynorthwyydd yn galw ar gydran technoleg iaith sy’n cynhyrchu crynodeb o’r canlyniad ar ffurf brawddegau sy’n ramadegol gywir, darllenadwy a dealladwy – cynhyrchu iaith naturiol(natural language generation).
- Yn olaf mae meddalwedd y cynorthwyydd yn galw ar gydran testun-i-leferydd(text-to-speech / TTS) sy’n trosi’r testun i mewn i’r sain sy’n cael ei ‘lefaru’ yn ôl i’r defnyddiwr mewn llais sydd i’w glywed mor naturiol a phosib i’r glust.
Enghraifft 2 – Dadansoddi a Deall Testun
Mae llawer o gwmnïau yn defnyddio technolegau iaith i ddadansoddi ac echdynnu gwybodaeth o gasgliadau enfawr o ddata anstrwythuredig sy’n bodoli ar ffurf testun. Caiff y casgliadau hyn eu casglu’n ddi-baid o wahanol ffynonellau fel gwefannau cymdeithasol, newyddion ar-lein a chasgliadau agored gan sefydliadau cyhoeddus. Defnyddir sawl math gwahanol o dechnoleg iaith i sicrhau pob dealltwriaeth bosibl o’r data.
Caiff technoleg adnabod endidau(entity recognition) ei defnyddio i adnabod enwau pobl, enwau lleoedd ac enwau cynnyrch o fewn y data, a defnyddir technoleg echdynnu cysyniadau(concept extraction) i ganfod prif pynciau testun. Mae rhain yn ddefnyddiol ar gyfer technolegau pellach sy’n mynegeio(indexing) neu’n crynodebu(summarization).
Gellir defnyddio technegau dadansoddi sentiment(sentiment analysis) er mwyn awtomeiddio dehongli barn ac agweddau a fynegwyd gan unigolion o fewn adolygiadau cwsmeriaid neu geisiadau am gymorth o fewn y data.
Enghraifft 3 – Cyfieithu Peirianyddol
Cyfieithu peirianyddol(machine translation / MT) yw gallu cyfrifiadur i gyfieithu testun o un iaith ddynol (yn y Saesneg, dyweder), i iaith ddynol arall (er enghraifft y Gymraeg).
Ers iddo ymddangos ar gyfer y Gymraeg dros ddegawd yn ôl, mae’r ddarpariaeth wedi cynorthwyo, ac ar adegau gythruddo, siaradwyr a chyfieithwyr Cymraeg. Achosodd y ddarpariaeth honedig gyntaf gan TranExp a’u cynnyrch InterTrans wallau a phroblemau ddi-baid4. Gwellodd y sefyllfa pan ymddangosodd Google Translate Cymraeg yn 2009 i fod a safon ac argaeledd digonol, o leiaf ar gyfer bras gyfieithu testunau cyffredinol.
Bellach, mae darpariaethau cyfieithu peirianyddol eraill ar gyfer y Gymraeg yn bodoli, gan gynnwys y modd i gyfieithwyr gynhyrchu a defnyddio eu peiriannau cyfieithu eu hunain, os oes ganddynt ddigon o ddata dwyieithog ac ychydig bach o wybodaeth dechnolegol.
Trosolwg o’r prif ddulliau a ddefnyddir gan dechnolegau iaith
Y tri dull amlycaf a ddefnyddir i weithredu technolegau iaith yw dulliau ar sail rheolau(rule-based approaches), ystadegaeth(statistics),dysgu peirianyddol(machine learning) a dysgu dwfn(deep learning). Mae’r dulliau angen un ai wybodaeth ieithyddol fanwl gywir neu gasgliadau enfawr o ddata o safon addas. Gellir cyfuno dau neu dri dull i greu dulliau hybrid sy’n manteisio ar gryfderau’r adnoddau sydd ar gael i wella’r canlyniadau o’u cymharu gyda defnyddio un dull yn unig.
Dulliau rheolau
Yn hanesyddol, rhoddwyd cychwyn ar wireddu rhai technolegau iaith gyda dulliau ar sail rheolau. Golyga hyn fod rhaid i fodau dynol, arbenigwyr iaith rhan amlaf, saernïo rheolau a data strwythuredig megis geiriaduron electronig i’w bwydo i mewn i’r cyfrifiadur, er enghraifft, rheolau gramadeg ar gyfer gwirydd gramadeg.
Gall y dulliau hyn roi canlyniadau da iawn mewn rhai meysydd, ond maent yn llafurus iawn i’w gweithredu, ac yn ddrud i’w datblygu a’u cynnal oherwydd y gost ddynol. Dim ond ieithoedd sydd â marchnad fasnachol ddigon mawr neu gefnogaeth ddigonol gan lywodraeth sydd wedi medru fforddio dilyn y trywydd yma.
Dulliau ystadegol
Wrth i faint a gallu cyfrifiaduron dyfu ar droad yr unfed ganrif ar hugain, sylweddolwyd fod modd defnyddio mynegiant o debygolrwydd neu fodelau ystadegol i gael gwell canlyniadau na dulliau rheolau i ddarparu technoleg iaith benodol.
Seilir y ddull ystadegol ar ddamcaniaeth syml Bayes :
P(W|O)=P(O|W) P(W)
Hynny yw, mae modd i fodel gynnig y gair (W) mwyaf tebygol o ganlyniad i arsylwad (O)
P(W|O)
drwy luosi’r tebygolrwyddau sydd wedi’u cyfrifo o’r dystiolaeth sydd ar gael (sef y ddata hyfforddi), sef tebygolrwydd arsylwad o ganlyniad i’r gair
P(O|W)
a’r tebygolrwydd o’r gair ei hun
P(W)
Does dim angen cymaint o wybodaeth ieithyddol gan fodau dynol wrth weithio gyda dulliau ystadegol o’r fath, ond yr anfantais yw fod angen casgliadau mawr o ddata ieithyddol er mwyn hyfforddi modelau defnyddiol.
Dulliau rhwydweithiau niwral
Er y gwelwyd cynnydd sylweddol yng ngallu technolegau iaith ar sail dulliau ystadegol a damcaniaeth Bayes, sylweddolwyd nad oedd modd gwella’r canlyniadau y tu hwnt i uchafswm cadarn.
Felly yn yr ychydig flynyddoedd diwethaf, mae hen ymchwil ar efelychu strwythur yr ymennydd yn gyfrifiadurol wedi’i atgyfodi i ‘ddysgu’ rhwydweithiau niwral artiffisial i gyflawni tasgau technolegau iaith gan ddwyn canlyniadau llawer iawn gwell. Yn wir, mae’r canlyniadau gymaint gwell, mae’r dulliau dysgu dwfn, sy’n rhan o ddysgu peirianyddol a ddeallusrwydd artiffisial(artificial intelligence) wedi chwyldroi’r maes.
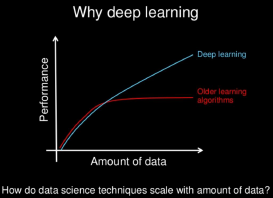
Ffigur 1 – Why Deep Learning.
Sleid gan Andrew Ng – https://www.slideshare.net/ExtractConf – Cedwir pob hawl
Eu gwendid yw bod angen adnoddau uwch-gyfrifiadura sylweddol i hyfforddi’r rhwydweithiau, ac o ran ieithoedd llai eu hadnoddau fel y Gymraeg, setiau data gwirioneddol anferth er mwyn gallu hyfforddi modelau o safon gwell. Nid yw’r data hynny bob amser ar gael yn hawdd ac felly mae lle o hyd i’r dulliau blaenorol o wireddu technolegau iaith, neu gyfuniad ohonynt.
4 Scymraeg (Cyfieithu doniol – gynt): https://maes-e.com/viewtopic.php?f=3&t=5433&start=510#p384904 (cyrchwyd Chwefror 2018)