


Mae prosesu iaith naturiol (Natural Language Processing, neu NLP) yn faes pwnc sy’n astudio’r rhyngweithio rhwng cyfrifiaduron ac ieithoedd dynol. Yn bennaf mae’n galluogi cyfrifiaduron i brosesu a dadansoddi iaith naturiol ar ffurf testun. Mae’n faes sylfaenol a hanfodol ar gyfer datblygu nifer o dechnolegau iaith.
Rhai o’r swyddogaethau defnyddiol a gyflawnir gan gydrannau’r maes yw gwirio gramadeg, dosbarthu a chrynhoi dogfennau, deall ystyr neu fwriad, dehongli sentiment, dysgu ffeithiau ac ateb cwestiynau yn eu cylch a chynhyrchu testunau newydd.
Er mwyn i gyfrifiaduron fedru cyflawni’r rhain, rhaid trefnu a strwythuro’r wybodaeth sydd o fewn y testun mewn ffordd y gall cyfrifiadur ei dadansoddi a’i halldynnu yn nes ymlaen. Yn ffodus mae llawer o adnoddau cyfrifiadurol eisoes ar gael sydd wedi’u dwyn at ei gilydd yn becynnau neu lyfrgelloedd meddalwedd. Enwir y rhain un ai’n ‘cit offer iaith naturiol’ (natural Language toolkit) neu’n ‘llyfrgell adnoddau prosesu iaith’ (language processing resource library). Mae llawer o’r rhain ar gael dan drwyddedau agored, ac maent yn ddefnyddiol i ddatblygwyr o bob math. Mae’r rhan fwyaf ohonynt wedi cychwyn eu taith fel citiau ar gyfer y Saesneg, ond bellach datblygwyd nifer o gydrannau ar gyfer ieithoedd eraill, gan gynnwys y Gymraeg.
Dyma dri o’r llyfrgelloedd mwyaf adnabyddus ar gyfer y Saesneg:
- Natural Language Toolkit (NLTK). Ysgrifennwyd yn iaith codio Python gyda modiwlau ar gyfer prosesu testun, dosbarthu, tocyneiddio, bonio, parsio a thagio7.
- Apache OpenNLP. Datblygwyd y cit hwn yn iaith codio Java ar gyfer dysgu peirianyddol ac mae’n darparu cydrannau megis tocyneiddwyr, segmentu brawddegau, parsio, adnabod ymadroddion enwol, ac alldynnu endidau enwol8.
- Stanford NLP. Dyma gyfres o offer NLP sy’n darparu tagio rhannau ymadrodd, teclyn adnabod endidau enwol, dadansoddwr sentiment, a mwy9.
Cydrannau sylfaenol llyfrgell prosesu iaith naturiol
Defnyddir nifer o’r cydrannau hyn gyda’i gilydd i greu llawer o offer ieithyddol i hwyluso defnyddio neu gyfathrebu gyda chyfrifiaduron, er enghraifft, gwirwyr sillafu a gramadeg.
Dyma esboniad o rai o’r cydrannau a ystyrir yn bwysig ar gyfer dadansoddi a phrosesu iaith:
Segmentiwr (Segmenter)
Mae segmentiwr yn ddarn o feddalwedd sy’n canfod ffiniau brawddegau ac sydd felly’n medru torri darn o destun yn ddarnau llai ar lefel brawddeg. Mae’n gwneud yr hyn sy’n cael ei alw hefyd yn ddadamwyso ffiniau brawddegau(sentence boundary disambiguation). Gall segment fod yn deitl, yn bwynt bwled neu’n ddilyniant tebyg o eiriau sy’n ystyrlon ac yn sefyll ar wahân i’r geiriau o’i flaen ac ar ei ôl. Gall hyn swnio’n syml mewn iaith fel y Gymraeg sy’n defnyddio’r nod ‘.’ fel atalnod llawn i ddynodi diwedd brawddeg, ond hyd yn oed yma gall fod yn fwy cymhleth na hynny gan fod ‘.’ hefyd yn cael ei ddefnyddio o fewn brawddeg, er enghraifft gyda byrfoddau fel ‘e.e.’ a ‘Dr.’ ac o fewn rhifau fel ‘1.23’ i gynrychioli’r pwynt degol. Yn ogystal, ni fydd rhai segmentau fel teitlau a phenawdau dogfennau yn defnyddio atalnod llawn i ddynodi eu diwedd felly ni ellir dibynnu yn llwyr ar ei bresenoldeb.
Tocyneiddiwr (Tokenizer)
Ystyr tocyneiddio wrth ddadansoddi iaith yw gwahanu a dosbarthu rhannau o nodau (llythrennau, rhifau a symbolau) sydd o fewn segment, er mwyn eu cyflwyno i’w prosesu ymhellach. Yn ymarferol, mewn iaith fel y Gymraeg, golyga hyn yn syml wahanu geiriau oddi wrth ei gilydd, ond gall fod yn fwy cymhleth mewn ieithoedd lle na cheir bwlch rhwng geiriau, megis Mandarin, a ieithoedd cyflynol (agglutinative) megis Coreeg. Hyd yn oed mewn ieithoedd fel y Gymraeg, gall nodweddion fel atalnodi, cywasgu neu gysylltnodi geiriau beri problemau sy’n galw am awtomeiddio’r broses o docyneiddio.

Ffigur2- Enghraifft syml o docyneiddio yn Gymraeg mewn sgema XML ar gyfer y llinell
“Mae’r awdurdodau wrthi’n ystyried y cynlluniau”
Lemateiddiwr (Lemmatizer)
Mae lemateiddiwr yn ddarn o feddalwedd sy’n adnabod pob ffurf bosib ar air sy’n medru cael ei ffurfdroi (inflect) yn ôl ei leoliad mewn brawddeg. Er enghraifft, mae gan air fel ci (dog) yn y Gymraeg 8 ffurf bosibl, o gyfrif y ffurfiau unigol a lluosog, a phob treiglad posibl:
ci, gi, chi, nghi, cŵn, gŵn, chŵn, nghŵn.
Mae nifer y ffurfiau posib gyda berfau yn fwy fyth, gan fod hynny’n golygu pob rhediad posibl ym mhob amser y ferf, ynghyd â’r holl dreigladau posibl. Er enghraifft, mae tabl wedi’i symleiddio o rediadau posibl y ferf ‘canu’ isod yn dangos 46 ffurf, heb gyfrif ffurfiau sydd yn edrych yn arwynebol yr un fath ond yn cynrychioli amserau gwahanol, megis ‘canwn’ fel person cyntaf lluosog presennol, a ‘canwn’ fel person cyntaf unigol amherffaith. O ychwanegu treigliadau meddal, llaes a thrwynol at y ffurfiau hynny hefyd, dyna gyfanswm o 138 ffurf bosibl. Dylai lemateiddiwr fedru delio gyda phob un o’r ffurfiau hynny, a’u olrhain yn ôl i’r berfenw ‘canu’.
| Presennol | Presennol Dibynnol | Dyfodol
(anffurfiol) |
Gorffennol (ffurfiol) | Gorffennol
(anffurfiol) |
Amherffaith | Gorberffaith |
| canaf | canwyf | canaf | cenais | canes | canwn | canaswn |
| ceni | cenych | cani | cenaist | canest | canit | canasit |
| cân, cana | cano | caniff, canith | canodd | canodd | canai | canasai |
| canwn | canom | canwn | canasom | canon | canem | canasem |
| cenwch | canoch | canwch | canasoch | canoch | canech | canasech |
| canant | canont | canan | canasant | canon | canent | canasent |
| cenir | caner | canwyd | cenid | canasid |
Ystyrir mai’r lema, neu’r ffurf graidd ar y gair, yw’r ffurf sydd fel arfer (ond nid bob amser) yn cael ei defnyddio fel dangosair mewn geiriadur traddodiadol. Weithiau, lle ceir ffurfiau afreolaidd i eiriau, nid oes cysylltiad rhwng geirffurf â’r lema, e.e. ‘cystal’, ‘gwell’ a ‘gorau’ fel graddau cyfartal, cymharol ac eithaf o’r ansoddair ‘da’, ond bydd lemateiddiwr yn eu clystyru gyda’i gilydd er hynny.
O redeg lemateiddiwr dros ‘Mae hen wlad fy nhadau yn annwyl i mi’ byddem yn cael:
| Mae | > | bod |
| hen | – | hen |
| wlad | > | gwlad |
| fy | – | fy |
| nhadau | > | tad |
| yn | – | yn |
| annwyl | – | annwyl |
| i | – | i |
| mi | – | mi |
Boniwr (Stemmer)
Ar gyfer rhai ieithoedd fel y Saesneg, ystyrir bod arf sy’n canfod bôn gair yn ddigonol ar gyfer canfod y rhan fwyaf o’i ffurfdroadau. Mae boniwr yn symlach na lemateiddiwr gan ei fod yn unig yn edrych ar olddodiaid gair ac yn torri’r rheiny er mwyn canfod y ffurf graidd. Ar y llaw arall, yn wahanol i lemateiddiwr, gall ganfod geiriau sy’n perthyn i’w gilydd oherwydd eu bod yn rhannu’r un gwraidd, e.e. llawen, llawenydd, llawenhau, llawenychu. Fodd bynnag, y mae affeithiad (vowel affection) yn Gymraeg, sy’n peri i lafariaid mewnol newid dan rai amgylchiadau, e.e. cyfaill, cyfeillion, cyfeillgar yn ei wneud yn fwy cymhleth i’w wireddu. Mae treigliadau hefyd yn gwneud bonwyr yn anymarferol ar gyfer y Gymraeg. Ni fyddai boniwr er enghraifft wedi medru adnabod ‘mae’, ‘wlad’ na ‘nhadau’ yn llinell gyntaf yr anthem genedlaethol.
Tagiwr rhannau ymadrodd (Part of speech tagger, PoS tagger)
Un o’r arfau mwyaf defnyddiol ar gyfer dadansoddi iaith yw medru adnabod rhannau ymadrodd geiriau unigol o fewn darn o destun. Mae tagio rhannau ymadrodd yn golygu marcio pob gair mewn testun neu gorpws gyda’i gategori gramadegol priodol. Ar ei lefel symlaf, gall y categorïau gramadegol hyn gynnwys berfau, enwau, ansoddeiriau, adferfau, arddodiaid, ac ati. Gan fod mwy nag un ffordd o ddadansoddi ac o ddisgrifio gramadeg iaith, ceir hefyd amryw ffyrdd gwahanol o greu cynlluniau tagio rhannau ymadrodd, yn dibynnu ar chwaeth y sawl sy’n cynllunio’r tagiwr, a’r pwrpas fydd i’r tagiwr o fewn prosesu iaith.
Mae categorïau gramadegol yn amrywio rhwng ieithoedd, er enghraifft, ceir bannod amhendant (‘a’ ac ‘an’) yn Saesneg, ond ni cheir rhan ymadrodd cyfatebol yn y Gymraeg. Ceir dwy genedl i enwau yn Gymraeg, sef benywaidd a gwrywaidd, ond ceir tair cenedl y enwau mewn Almaeneg, sef benywaidd, gwrywaidd a neodr, ac ni cheir cenedl i enwau yn Saesneg o gwbl. Mae gan ieithoedd eraill eto, yn enwedig rhai morffolegol gyfoethog, gategorïau gramadegol gwahanol iawn, ac mae creu tagiwr rhannau ymadrodd yn her sylweddol wrth geisio creu offer prosesu iaith naturiol ar eu cyfer.
Gall creu tagiwr rhannau ymadrodd fod yn her i unrhyw iaith oherwydd amwyster rhai geiriau a geirffurfiau. Un o’r geiriau anoddaf i’w ddadamwyso yn Gymraeg yw’r gair ‘yn’, sy’n medru bod yn arddodiad rhediadol (‘ynof’, ‘ynot’ etc); yn eiryn berfenwol (‘yn canu’ etc); yn eiryn traethiadol (‘yn annwyl’ etc); ac yn nifer o rannau ymadrodd llai cyffredin. Nid dim ond ffurfiau craidd geiriau sy’n medru peri amwyster. Mae’r amwyster yn cynyddu’n sylweddol os ystyrir ffurfiau cymharol, ffurfiau lluosog, ffurfiau wedi’u rhedeg a/neu eu treiglo, ac ati. Er enghraifft, gall ‘gŵn’ fod yn enw gwrywaidd yn golygu math arbennig o wisg, gall hefyd fod yn ffurf ar yr enw lluosog ‘cŵn’ wedi’i dreiglo’n feddal. Yr hyn sy’n galluogi adnabod rhannau ymadrodd yn gywir yw cyd-destun geiriau mewn brawddeg, a’u perthynas gyda’r geiriau o’u cwmpas. Felly mae modd adnabod ‘gŵn’ fel enw gwrywaidd unigol mewn brawddeg fel ‘Roedd yn gwisgo gŵn porffor llaes at ei draed’ o’i gymharu â ‘Roedd nifer o gŵn yn cyfarth yn ffyrnig o’i gwmpas’ lle mae ‘gŵn’ yn ffurf luosog o’r enw ‘ci’ wedi’i dreiglo’n feddal.
Dyma enghraifft o’r llinell ‘Mae hen wlad fy nhadau yn annwyl i mi’ wedi cael ei redeg drwy dagiwr rhannau ymadrodd Cysill:
| Mae | (bod) ff. berf |
| hen | ans + ans p. |
| wlad | (gwlad) eb, treiglad meddal |
| fy | rhagenw |
| nhadau | (tadau – tad) e. llu, treiglad trwynol |
| yn | ardd + yn traethiadol + atod. berfol |
| annwyl | ans |
| i | ardd + rhagenw |
| mi | rhagenw + geiryn |
Talpiwr (Chunker)
Teclyn adnabod clystyrau o eiriau fel ymadroddion enwol, ymadroddion berfol, endidau enwol a thermau aml air yw talpiwr. Weithiau caiff ei alw yn barsiwr bas (shallow parser) am ei fod yn gallu gwneud rhai o’r un swyddogaethau â pharsiwr llawn, ond heb fod mor gymhleth. Yn y llinell ‘Mae hen wlad fy nhadau yn annwyl i mi’ gellir ystyried ‘hen wlad fy nhadau’ yn un talp, gan ei fod yn digwydd yn aml fel ymadrodd gyda’r un dilyniant geiriau.
Ystyrir talpiwr yn arf defnyddiol i gael hyd i endidau sy’n cynnwys mwy nag un gair ond sy’n perthyn i’w gilydd yn gysyniadol, yn enwedig os oes iddynt ystyr gwahanol fel ymadrodd i ystyr y geiriau unigol ar ei pen eu hun, e.e. mae ‘llygoden fawr’ yn Gymraeg yn golygu yr un peth â ‘rat’ yn Saesneg, sy’n anifail gwahanol i ‘big mouse’ sef yr hyn fyddai’r cyfieithiad Saesneg o gyfieithu’r ddau air yn unigol ar wahân.
Fel rheol defnyddir tagiwr rhannau ymadrodd i dagio testun neu gorpws yn gyntaf, a wedyn defnyddio talpiwr fel ail gam yn y broses o’i ddadansoddi. Mae algorithmau talpio syml yn canfod patrymau ailadroddus mewn clystyrau o eiriau, ac yn benthyg o syniadaeth techneg mynegiadau rheolaidd (regular expressions) a ddefnyddir mewn meysydd eraill fel cyfrifiadura damcaniaethol a theori iaith ffurfiol (formal language theory). Bellach gall talpwyr mwy soffistigedig ddadansoddi’r cyd-destun hefyd ac felly roi canlyniadau sy’n adlewyrchu’r talpiau fel unedau o ystyr, yn hytrach na chyfateb patrymau yn unig.
Parsiwr (Parser)
Diben parsiwr yw dadansoddi brawddeg neu ddilyniant o eiriau yn ôl yr elfennau llai ynddo, er mwyn deall y gystrawen ac felly hefyd gynorthwyo i ddeall yr ystyr. Arferid gwneud hyn â llaw, gan dynnu llun neu ddiagram o’r gwahanol elfennau a’u perthynas â’r frawddeg, ond bellach gellir gwneud y dadansoddiad yma yn gyfrifiadurol. Gall modelau iaith sydd wedi’u hyfforddi ar ddigon o destun anodedig safon aur (gold standard) ddadansoddi brawddegau yn gywir iawn erbyn hyn yn y Saesneg.
Mae modd creu nifer o ffyrdd gwahanol o barsio brawddegau, a’r ddau ddull mwyaf poblogaidd yw parsio dibyniaethau (dependency parsing) a pharsio cyfansoddion (constituency parsing). Mae’r ddau ddull yn defnyddio strwythur coeden, canghennau a dail i ddarlunio’r berthynas rhwng y gwahanol elfennau, ond mae’r dehongli yn wahanol. Mae’r ddau ddull yn tagio rhannau ymadrodd (i raddau gwahanol o fanylder) ac mae’r union fodd y gwneir hyn yn amrywio o fewn y ddau ddull.
Mae modd gweld y gwahaniaeth rhwng cystrawen gwahanol ieithoedd yn weledol wrth barsio yn ôl y ddau ddull, fel wrth gymharu strwythur y parsiadau syml isod yn y Gymraeg a’r Saesneg.
Mewn parsio cyfansoddion mae’r strwythur yn cwmpasu’r goeden gyfan, gan ddechrau o’r frawddeg (=S) a diweddu ym mhob un o’r dail. Isod defnyddir y byrfoddau canlynol yn y goeden:
- NP am ymadrodd enwol (noun phrase). Gall ymadroddion enwol fod yn oddrych a gwrthrych brawddeg.
- VP am ymadrodd berfol (verb phrase), sydd yma yn chwarae rhan traethiad (predicate).
- V am ferf.
- D am y banodolyn(determiner), yma ar ffurf y fannod.
- N am enw.
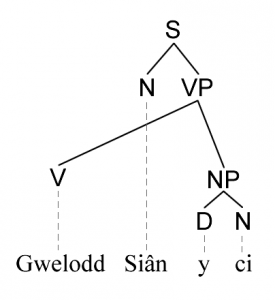
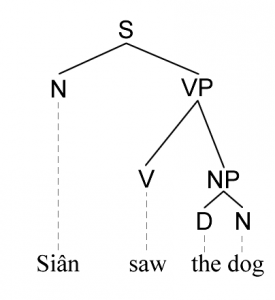
Yn y strwythur uchod, mae’r frawddeg (S) yn wraidd, y canghennau sy’n cysylltu dau gwgn (node) yn ganghennau (VP ac NP), a’r tocynau lecsigol (N,V, D ac N) ar y diwedd yn ddail.
Mewn parsio dibyniaethau ni cheir gwahaniaeth rhwng cangen a dail, ac felly mae’r strwythur yn symlach. Mae fel petai pob cwgn yn ddeilen yn ôl y dehongliad hwn. Ni cheir y categorïau brawddeg, ymadrodd enwol nac ymadrodd berfol yma.
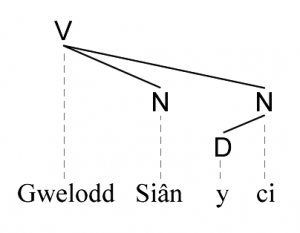
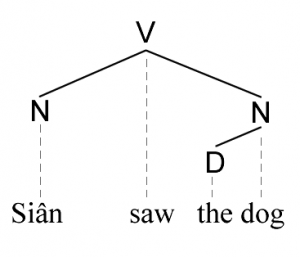
Fodd bynnag ceir strwythur cyfansoddion mewn parsio dibyniaethau yr un fath ag mewn parsio cyfansoddion, gyda phob is-goeden o’r goeden yn gyfansoddyn. Ar hyn o bryd, parsio dibyniaethau yw’r dull mwyaf poblogaidd o barsio testunau wrth brosesu iaith naturiol.
Modelau iaith (Language Models)
Mae modelau iaith yn un o’r cydrannau pwysicaf ar gyfer prosesu iaith naturiol. Maent yn bwysig ar gyfer gwirio sillafu, adnabod llawysgrifen, adnabod nodau gweledol (OCR), cyfieithu peirianyddol, ac adnabod lleferydd. Mae ganddynt rôl ganolog hefyd mewn Deallusrwydd Artiffisial a Dysgu Peirianyddol, er mwyn deall a dadansoddi ieithoedd dynol.
Mae iaith naturiol yn benagored, ac mae siaradwyr yn ddyfeisgar wrth ei defnyddio. Maent yn creu cyfuniadau newydd o eiriau yn gyson, yn ymestyn ystyr geiriau, a hyd yn oed yn dyfeisio geiriau newydd mewn ffyrdd creadigol sy’n anodd i beiriannau eu deall a’u dadansoddi. Canlyniad hyn yw fod angen ffordd sy’n patrymu neu’n modelu iaith lle gall ddod ar draws cyfuniadau newydd o eiriau a brawddegau, yn hytrach na dim ond cydweddu gyda’r union eiriad sydd eisoes yn y cof neu’r model.
Yn ei hanfod, yr hyn mae modelu iaith yn ei wneud yw penderfynu ar debygolrwydd dilyniant penodol o docynnau, neu unedau ieithyddol, e.e. geiriau a brawddegau, o fewn testun. Mae’n gallu dweud, er enghraifft, fod ‘annwyl’ yn fwy tebygol nac ‘annwyd’ i fod y gair nesaf yn y llinell ‘Mae hen wlad fy nhadau yn ….’. Byddai hefyd yn gallu dweud fod ‘Rwy’n canu cân/anthem/emyn/pennill yn fwy tebygol na ‘Rwy’n canu car/gallem/dibyn/pendil’. Wrth weithio gyda thechnoleg adnabod lleferydd, gall weithio allan fod brawddeg fel ‘Mae hen wlad fy nhadau’ yn fwy tebygol na rhywbeth fel ‘Maen ên lad yn nadu’.
Tan yn ddiweddar, y ffordd o greu modelau iaith oedd drwy ddulliau ystadegol i ddosbarthu tebygolrwydd (P) dros linynnau i geisio adlewyrchu pa mor aml mae llinyn (S) yn digwydd mewn brawddeg. Mae modd felly fynegi gwahanol ffenomenâu iaith yn nhermau paramedrau syml mewn model ystadegol. Model n-gram yw’r model mwyaf cyffredin yn y dull ystadegol, a cheir sawl math gwahanol ohono, sy’n ddefnyddiol mewn meysydd y tu hwnt i brosesu iaith naturiol. Ei brif broblem yw diffyg data wrth i’r n-gramau gynyddu, hynny yw, gall fod yn gymharol hawdd modelu deugramau a thrigramau, ond wrth fynd i rifau uwch, bydd llai o enghreifftiau ar gael i hyfforddi’r model.
Bellach defnyddir dulliau rhwydweithiau niwral a dysgu dwfn ar gyfer modelu defnydd iaith naturiol gan eu bod yn dysgu i drawsffurfio gwybodaeth tebygolrwydd i greu allbwn dymuniedig mewn modd sy’n cyffredinoli i ddata na welwyd yn ystod y broses hyfforddi. Gall gwahanol fathau o hyfforddi a phensaernïaeth rhwydweithiau niwral gynnwys manteision cynhenid at ddibenion modelu. Er enghraifft, gall hyfforddi heb oruchwyliaeth glystyru geiriau i ystyron tebyg a dysgu’r berthynas rhyngddynt tra bo rhwydweithiau niwral ailadroddol (recurrent neural networks) yn modelu’r cyd-destun ehangach ar lefel brawddeg, dogfen neu gorpws, sy’n ddefnyddiol ar gyfer adnabod pwnc (topic identification) yn awtomatig.
Corpora testun, data mawr ac adnoddau eraill
Un peth sy’n gyffredin i’r holl ddulliau prosesu iaith naturiol a’r offer ar gyfer gwneud hynny yw fod angen llawer iawn o ddata ieithyddol ar gyfer y gwahanol dasgau. Erbyn hyn nid yw corpws o filiwn neu hyd yn oed biliwn o eiriau yn ddigonol i roi’r canlyniadau gorau. Er enghraifft, hyfforddwyd y rhaglen GPT2 sy’n medru cynhyrchu newyddion ffug credadwy iawn yn Saesneg ar set data sy’n cynnwys 10 miliwn o erthyglau o’r we10Roedd y casgliad testun hwn yn 40GB mewn maint, yn cyfateb i tua 35,000 copi o’r nofel Moby Dick11
Mae’n anodd i ieithoedd bach fel y Gymraeg gael gafael ar ddata o’r maint yna, a cheir amheuaeth am faterion hawlfraint a statws casglu a rhyddhau rhai mathau o ddata, sy’n ychwanegu at yr anhawster o gael data digonol ar gyfer rhai tasgau. Ar hyn o bryd corpws Cysill Ar-lein yw’r corpws Cymraeg mwyaf sydd ar gael i greu modelau iaith ac offer tebyg12, gan ei fod yn cynnwys dros 150 miliwn o eiriau ac yn dal i dyfu.
Fod bynnag, oherwydd pryderon am sensitifrwydd y data sydd wedi’i fewnbynnu i Cysill Ar-lein nid oes modd i Brifysgol Bangor rannu testunau’r corpws cyfan. Ceir corpora eraill llai at ddibenion penodol, rhai ohonynt wedi’u cynllunio ar gyfer dadansoddiadau ieithyddol yn hytrach na fel adnoddau technolegau iaith. Corpora felly yw corpora iaith CEG13, Siarad14 CorCenCC15sydd ar hyn o bryd yn cael ei ddatblygu yn samplau o wahanol fathau o iaith, ac a fydd yn cynnwys 10 miliwn o eiriau pan fydd wedi’i gwblhau.
At ddibenion prosesu iaith, yn aml crëir corpws safon aur (gold standard corpus) sy’n cael ei anodi’n ofalus â llaw yn unol â’r safon y penderfynwyd ei ddilyn. Caiff hwnnw wedyn ei ddefnyddio i hyfforddi algorithmau er mwyn anodi yn awtomatig. Mae’n arfer hefyd cadw rhan o’r corpws safon aur yn ôl er mwyn gallu gwerthuso’r modelau a hyfforddwyd ar y corpws ar ddata nad yw’r model wedi’i weld o’r blaen. Mae anodi â llaw yn waith llafurus, araf a drud, ond mae safon y gwaith hwn yn effeithio ar lwyddiant y gwaith awtomatig dilynol. Oherwydd hynny, mae anodi â llaw yn rhan hynod o bwysig o’r broses, ac yn un na lwyddwyd i’w throsglwyddo’n llawn i beiriannau hyd yn hyn.
Ar wahân i gorpora, mae adnoddau defnyddiol ar gyfer prosesu iaith yn cynnwys geiriaduron yn ogystal â rhestrau mwy sylfaenol fel rhestrau geiriau, rhestrau o enwau lleoedd, enwau pobl, sefydliadau a chwmnïau, rhestrau o ataleiriau (stoplists) a data tebyg mwy arbenigol. Erbyn hyn caiff llawer o’r rhain eu cynhyrchu’n awtomatig o gorpora wedi’u hanodi neu setiau data mawr, ac mae gwyddor geiriadura ei hun wedi newid i gael ei seilio ar dystiolaeth corpws.
7 Erthyglau o’r we gyda dolen iddynt o Reddit a hyn â hyn o ‘upvotes’. Roedd hynny’n fodd o sicrhau safon yr erthyglau.
8 Better language models and their implications.: https://blog.openai.com/better-language-models/
(cyrchwyd Chwefror 2019)
9 Prys, D., Prys G., and Jones, D.B. Cysill Ar-lein: A Corpus of Written Contemporary Welsh Compiled from an On-line Spelling and Grammar Checker. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016) Portoroz, Slofenia
http://www.lrec-conf.org/proceedings/lrec2016/summaries/513.html
10Erthyglau o’r we gyda dolen iddynt o Reddit a hyn â hyn o ‘upvotes’. Roedd hynny’n fodd o sicrhau safon yr erthyglau.
11Better language models and their implications.: https://blog.openai.com/better-language-models/
12 Prys, D., Prys G., and Jones, D.B. Cysill Ar-lein: A Corpus of Written Contemporary Welsh Compiled from an On-line Spelling and Grammar Checker. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016) Portoroz, Slofenia
13 Ellis, N. C., O’Dochartaigh, C., Hicks, W., Morgan, M., & Laporte, N. (2001). Cronfa Electroneg o Gymraeg (CEG): A 1 million word lexical database and frequency count for Welsh.: http://corpws.cymru/ceg/
14 Corpws SIARAD: http://bangortalk.org.uk/speakers.php?c=siarad (cyrchwyd Chwefror 2019)
15 Corpws Cenedlaethol Cymraeg Cyfoes : http://www.corcencc.cymru (cyrchwyd Chwefror 2019)