Moses-SMT is an open source machine translation system that was mainly developed at Edinburgh University. This resource allows you to develop your own machine translation engines for use in your translation projects by training it with any pre-existing corpora of parallel texts.
We at the Language Technologies Unit have used Moses-SMT in order to provide machine translation in our commercial offering CyfieithuCymru, which enables and supports efficient Welsh<>English translation within institutions.
Today we are releasing these Moses-SMT translation systems to you, as well as the data which was used to train them.
We are making our machine translation engines freely available because we believe that it’s vital for Welsh translators be able to own and develop their own machine translation infrastructure, and master these new disruptive technologies for full effect. This ambition was explained in our previous blog post.
In order to make the package as easy as possible to use, we’ve developed a simple system which only requires two commands to operate (providing that the necessary operating system and equipment are already installed!).
Before you go ahead however, we’d like to emphasize once more the importance of quality control – It is your responsibility to ensure that this machine translation software is used appropriately, including the use of careful post-editing (see Quality Issues).
Docker
 Docker is an open platform for developers and sysadmins to build, ship, and run distributed applications. Using Docker it will be easy to install and run Moses-SMT without adversely affecting any of your other installations.
Docker is an open platform for developers and sysadmins to build, ship, and run distributed applications. Using Docker it will be easy to install and run Moses-SMT without adversely affecting any of your other installations.
We have loaed our Moses-SMT to docker.com’s central registry.
You will need a version of Docker more recent than 1.0.1 on your Linux system. We usually use Ubuntu. Here is a video on YouTube that explains how you can install docker 1.3 on Ubuntu 14.04. If you would like to run your translation engine on a Windows computer or on a Mac OS X then you may be able to use Boot2Docker.
So, in Linux, the two commands are:
Command 1 : Installing Moses-SMT (with Docker)
$ docker pull techiaith/moses-smt
This will download and install the machine translation infrastructure into your Docker system.
When it has finished downloading, type ‘docker images’ to check that it’s been installed.
$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
techiaith/moses-smt latest 3dbad7f9aabf 41 hours ago 3.333 GB
$
Command 2 : Start a Translation Engine of Your Choice
The Language Technologies Unit has created translation engines by training them with data collected from open and public sources, such as the Proceedings of the Welsh Assembly and the Legislation on-line.
These engines have specific names and translation directions. The name of engine that was trained with Assembly data is ‘CofnodYCynulliad’, while the name of the engine trained with the Legislation on-line is ‘Deddfwriaeth’.
Here is the second command, with options set to select the ‘CofnodYCynulliad’ engine that translates from English to Welsh :
$ docker run --name moses-smt-cofnodycynulliad-en-cy -p 8080:8080 -p 8008:8008 techiaith/moses-smt start -e CofnodYCynulliad -s en -t cy
The system will initially download a file (around 3Gb in the case of the CofnodYCynulliad) before confirming that it is ready to start translating.
If you open your browser and go to http://127.0.0.1:8008 , a simple form should appear so that you can check whether or not the engine works as intended:

Training Data
The data collected by the Language Technologies Unit, which was used to train our Moses-SMT machines, is available below:



 Part of our Welsh Language Communications Infrastructure project is to improve the machine translation resources for leveraging some capabilities that are provided via English language based technologies.
Part of our Welsh Language Communications Infrastructure project is to improve the machine translation resources for leveraging some capabilities that are provided via English language based technologies.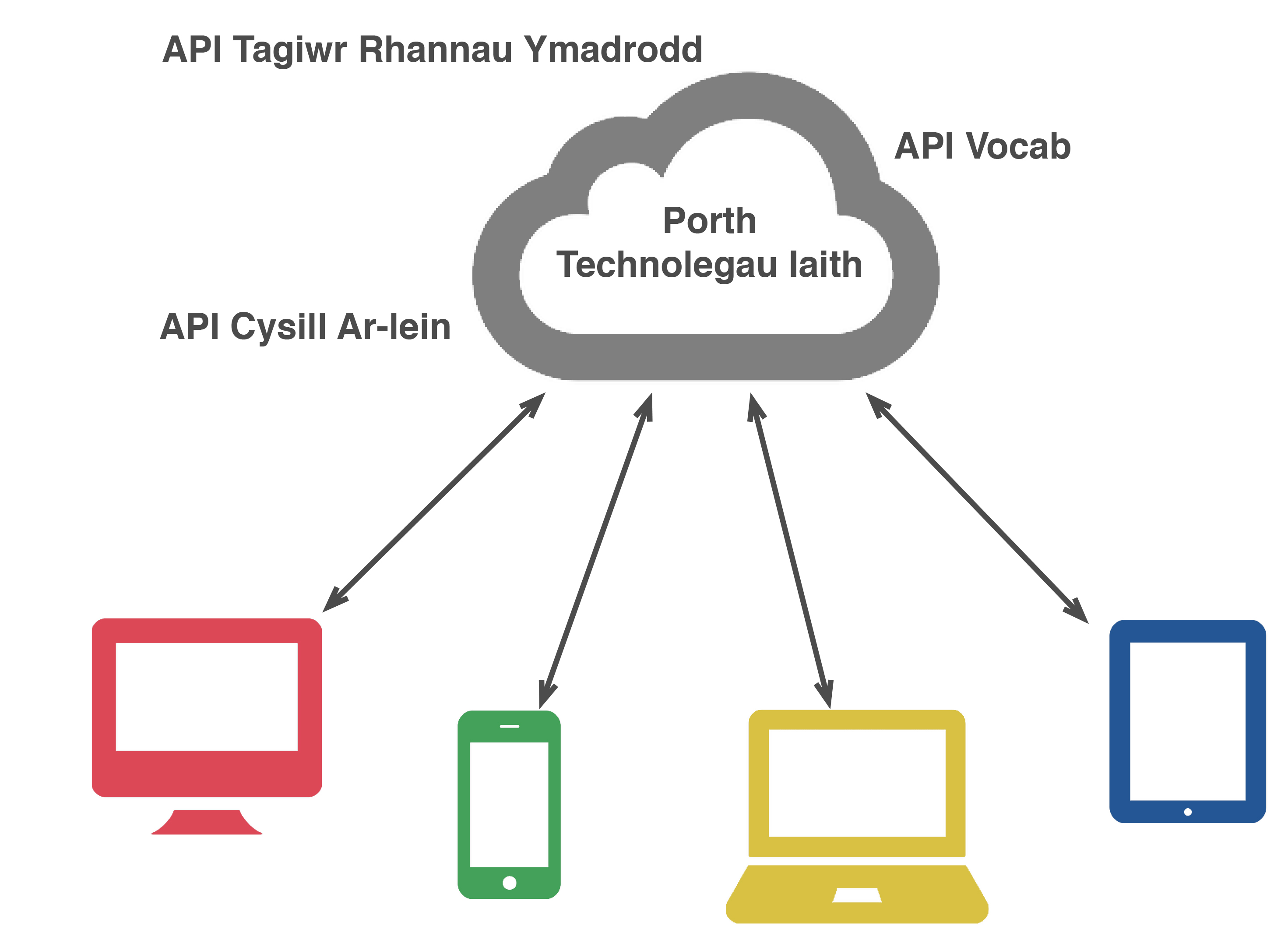 Similar to these other API services, you can get started by obtaining your API key (How to register for an API key) and follow the documentation and code examples we’ve prepared on GitHub. Please see: https://github.com/PorthTechnolegauIaith/moses-smt/blob/master/docs/APIArlein.md
Similar to these other API services, you can get started by obtaining your API key (How to register for an API key) and follow the documentation and code examples we’ve prepared on GitHub. Please see: https://github.com/PorthTechnolegauIaith/moses-smt/blob/master/docs/APIArlein.md

