


Trawsgrifiwr is a software program which transcribes Welsh speech to text. It is continuously beging revised and updated, and is now availabe on three platforms.
Firstly, the Trawsgrifiwr Ar-lein (on-line transcriber) is available here. You can either link to an external service such as YouTube to subtitle videos, click or drop in files using the on-line interface, or record voice directly from the microphone.
Secondly, Trawsgrifiwr is available as a skill in the Macsen Welsh Personal Assistant app.
Thirdly, you can access the Windows version from this page (see below).
The source code is also available on GitHub –
Trawsgrifiwr for Windows:
Trawsgrifiwr Ar-lein:
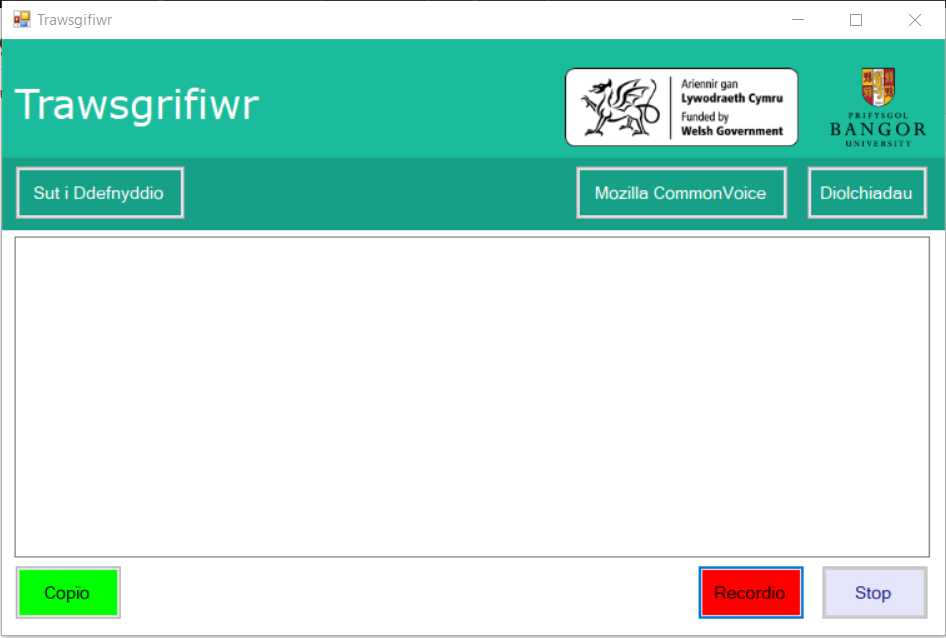
Trawsgrifiwr doesn’t yet recognise all your words correctly every time. In simple tests this revised version gets about 85% of words in a sentence spoken in standard Welsh correct. Results are given in a text box where you can correct and copy them to the clipboard in order to paste them into any software on your PC. The Trawsgrifiwr can also deal with subtitles on YouTube.
Download and execute the setup program from here.
Trawsgrifiwr was made possible thanks to various projects and cooperation between Mozilla, volunteers, and the Welsh Technologies Unit, Canolfan Bedwyr, Bangor University. Bangor University’s part of the work, including development of Trawsgrifiwr and Ap Macsen (the Welsh Personal Digital Assistant) was funded by the Welsh Government.
Trawsgrifiwr is mainly based on Mozilla’s DeepSpeech. DeepSpeech is a speech recognition engine that can be trained and included easily within any software. To learn more about DeepSpeech go to https://github.com/mozilla/deepspeech. The code for Trawsgrifiwr is available from:
Collecting huge amounts of recordings is crucial to training a speech recognition engine. We have done this mainly through the medium of Common Voice, Mozilla’s platform to collect people’s voices reading aloud specific sentences. We are very grateful to Rhoslyn Prys (meddal.com) who undertook many crowdsourcing campaigns as a volunteer, working with the Mentrau Iaith (Language Ventures), Cyngor Gwynedd local authority, and the National Library of Wales. We also wish to thank the Welsh Government for their publicity campaign, and to the multitude of participant across Wales and beyond who have also contributed their voices to the Welsh version of Common Voice.
We also thank the Centre Inria de Paris for the open source OSCAR corpus which includes a large collection of Welsh texts scraped from the web. We used the corpus to train models of Welsh vocabulary and phraseology in order to help the recognition process and to obtain greater accuracy. For more information, go to https://traces1.inria.fr/oscar/.