


Purpose of the wordlists
A requirement of the Welsh Government funded “Macsen” Speech Recognition project was that we publish wordlists of the 2,500 most common words written in Welsh, and the 500 most common English words used in Welsh. These wordlists are intended to help improve Welsh speech technology by identifying the most common words likely to be uttered for processing in a Welsh language transcription system. These wordlists will be used to test the ability of our prototype transcription once it is ready, and measure its ability to recognise these common words.
Other projects, such as that to develop the Bangor Siarad Corpus (http://bangortalk.org.uk/speakers.php?c=siarad), have followed lexical principles in assigning words to either Welsh or English categories, i.e. their evaluation of what is a ‘Welsh’ or an ‘English’ word has been based on their attestation or otherwise in Welsh or English dictionaries. We have added other principles for our wordlists, based on whether their pronunciation follows Welsh or English letter-to-sound rules, as we are specifically interested in improving the recognition and transcription of spoken Welsh.
Words and wordforms
Wordlists are often thought of as lists of canonical forms, or the headwords found in dictionary entries. However, in a language such as Welsh, which has many inflected forms, and in contrast to English which has far fewer inflections, we decided to publish lists of the wordforms and their frequency counts, rather than the canonical forms or lemmas. This will help identify the most common forms, as some wordforms are much more common than their lemma, e.g. ‘mae’ (3rd person singular of the verb ‘to be’), is much more common that its lemma ‘bod’. Sometimes more than one wordform deriving from the same lemma comes into the 2,500 top most commonly used words, e.g. the lemma ‘Mehefin’ (‘June’) and the wordform ‘Fehefin’ with its soft mutation, both come into the list of the top 2,500 wordforms in Welsh.
Welsh makes much use of apostrophes to merge two words and indicate missing vowels. Wordforms that include apostrophes are regarded as legitimate wordforms in the Welsh wordlist, since doing so will help Welsh speech recognition and the creation of a Welsh transcription system. As illustrations, the wordform ‘hi’n’ occurs 1,117719 times in the corpus, and the wordform ‘a’i’ occurs 1,05456 times. For the avoidance of ambiguity, apostrophes are shown as underscores in the wordlist, therefore ‘hi_n’ and ‘a͏_i’ are the forms shown in the Welsh wordlist.
Data sources
In order to gather objective evidence for the word frequency counts, we needed a Welsh corpus or corpora of sufficient size, if possible in the form of a balanced corpus. The largest Welsh corpus available for us was the Cysill Ar-lein Corpus (Prys, Prys a Jones 2016), which has by now reached over 200 million words and which continues to grow. It was created from texts input by users in order to check their spelling and grammar on-line, between 2009 and the present. It was not therefore intended as a balanced corpus, but it contains a great variety of text types, as Wooldridge’s (2011) analysis of it demonstrates:
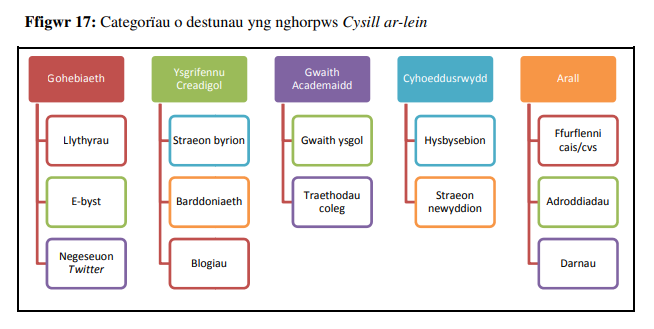
(This shows the categories of Correspondence, Creative Writing, Academic Work, Publicity and Other, with subcategories of letters, emails and Twitter messages; short stories, poetry and blogs; schoolwork and college essays; adverts and news stories; and job applications/cvs, reports and fragments).
The CEG Corpus (Ellis et al, 2001), was also examined, but although designed from the outset as a balanced corpus, it only contains one million words. Also, the original texts were collated during the early 1990s, and the vocabulary of Welsh has changed a great deal since then, with new words and concepts such as ‘rhyngrwyd’ (‘internet’) coming into the language.
The most common words in Welsh according to the CorcenCC project were also examined. This corpus will eventually contain 10 million words in a balanced corpus across different modalities, both written and spoken (http://www.corcencc.cymru/). This project is still ongoing, and at present there are only 3,597 unique wordforms and 14,876 in its demo list of wordforms, making for a comparatively small sample.
The most common wordforms at the top of the lists were compared across the three corpora, and were found to be markedly similar, with more divergence appearing further down. This helped confirm that the methodology used was basically sound. The Cysill Ar-lein Corpus was therefore used as the source of the Welsh wordforms, with the data being taken from the January 2019 version of the corpus.
Finding a source for the most common English words used in Welsh was more of a challenge. We examined the Siarad Corpus (Deucher et al, 2009), which is a speech corpus of spoken dialogue created explicitly to study code switching between Welsh and English. It contains 447,507 words, and an estimated 84% of the corpus is in Welsh, with 4% in English, with 13% undetermined. It was transcribed by hand, and the English words in it are tagged as English. We conducted a few experiments with this corpus, but the sample proved to be too small for a meaningful list of the 500 most common words in Welsh. Also, since it was in essence a speech corpus, the register used was very informal, in contrast to what is used in written texts, even informal written texts such as Twitter messages.
On the other hand, we observed that there were numerous English words in the Cysill Ar-lein Corpus. Many of them come from English sentences appearing in the middle of Welsh text, but after having excluded those from the list, a substantial number of English words remained, although they only formed a small part of the corpus. Compare, for example, the frequency count of 10,952,674 of the most common word in Welsh, namely ‘yn’, with 7,361 occurrences for the most common English words in the corpus, namely ‘the’ (note however that it is possible that some examples of the Welsh word ‘te’ (‘tea’) with the aspirate mutation are mixed in here). There were 11 English words each occurring 107 times in the Cysill Ar-lein Corpus, this being the lowest frequency wordcount to come within the 500 English words limit. The Cysill Ar-lein Corpus, January 2019 version, was also used to collate the wordlist of the most common English words in Welsh.
Where there are orthographic variations in Welsh, with more than one form accepted as legitimate, all legitimate forms coming within the 2,500 word limited were included in the list. For example, ‘siŵr’ (with the circumflex accent) occurs 54,228 times in the corpus, and ‘siwr’ (without the circumflex accent) occurs 24,009 times. Both forms are correct according to the University of Wales Welsh Dictionary. Therefore both forms were included since both occur with the 2,500 most frequently used Welsh words.
In the wordlists, each wordform has the number of times it occurs in the Cysill Ar-lein Corpus listed alongside.
Identifying Welsh, English and exceptions
In order to identify the Welsh words, and any words that should be classified as English words in the Cysill Ar-lein Corpus, the Hunspell Welsh and English lexicons were used for comparison. It was noted that some words could be both Welsh and English (e.g. ‘plant’), and if so it was presumed that they were more likely to be Welsh words in a corpus derived from Welsh language materials and tagged as such.
We used Langdetect CLD2 Google components to identify English phrases and sentences in the Cysill Ar-lein Corpus and to exclude them so as not to contaminate the data on individual words used in code switching. SRILM language modelling software was also used to count ngrams so if there were ambiguous words which could be either Welsh or English it was possible to see what was the language of the word in front of it. If that language was English, then it was more likely that the ambiguous word was also English, and we counted it as such, even though ambiguous words were otherwise counted as Welsh ones.
The words that made it to the top of the English list were also the most frequent English words in English in general, e.g. ‘the’, ‘of’, ‘and’. Many of these may come from named entities in the corpus, such as names of films and organisations, e.g. The Lion King, The Royal Society, and these were retained.
We do not claim that these methods have succeeded in every instance to identify Welsh and English words correctly. For example, as noted above, ‘the’ can be the mutated form of the Welsh word ‘te’, or ‘of’ above can be the mutated form of the Welsh word ‘gof’ (‘blacksmith’). However in the above contexts the English ‘the’ and ‘of’ were judged to be more common since they correlated with the cluster of most common English words rather than mutated form of ‘gof’ a ‘te’. On the other hand, the ambiguous ‘to’ was taken out of the English list and placed in the Welsh list (there are 7,990 examples of ‘to’ in the Cysill Ar-lein Corpus) because, on examining the collocations, the Welsh word ‘to’ (corresponding to English ‘roof’), the Welsh word was by far the most common occurrence.
Editorial judgement was used to move some named entities that had been tagged as Welsh by Hunspell, especially proper nouns (e.g. Jones, Williams) to the English list as they are pronounced according to English phonetic conventions. The basic principle used was that the Welsh list had to conform to how Welsh is pronounced according to Welsh letter-to-sound rules, and the English list had to conform to the letter-to-sound rules for English.
This also meant that some loanwords from English, perceived, according to some interpretations, to be part of code-switching between Welsh and English, are included as Welsh words. In the Cysill Ar-lein Corpus, the spelling of such words had been Welshified, e.g. ‘plîs’ (English: ‘please’), and ‘jyst’ (English: ‘just’). If this was the case, they were accepted as Welsh words for the purpose of these wordlists.
Some ambiguous words were not recognised as either Welsh or English because they did not occur in either of the two Hunspell lexicons. These were edited by hand and included in the correct list if they had the requisite word frequency count for inclusion.
Numbers (e.g. ‘2’) were excluded from the wordlists, unless they were written out fully as words, e.g. ‘dau’ or ‘dwy’ (masculine and feminine forms). All acronyms and abbreviations were also excluded, as any transcribing system would not be able to deal with these without further tokenization work.
Post-processing
There are many named entities in both the Welsh and the English wordlists. These are usually written with an initial capital letter in both languages. These were converted to lower case letters as the data was processed. An attempt was made to restore capitalization in named entities by comparing with Hunspell, which is case-sensitive. However, many words can be both common nouns and named entities, e.g. ‘gwyn’ a ‘Gwyn’ and ‘heather’ a ‘Heather’. In such cases, the common noun was prioritized over the named entity. There may well be instances where the named entity is the most common form, e.g. with ‘may’ in English, it is possible that the name of the former prime minister, Mrs May, is what is meant in many of the examples, or the month of May, as names of months also appear in the corpus.
Lastly, we decided to check the wordlists for any words with derogatory connotations, which should be removed from a publically available resource. We are happy to report that only one word needed to be excluded for this reason.
References
Prys, D., Prys G., and Jones, D.B. (2016) Cysill Ar-lein: A Corpus of Written Contemporary Welsh Compiled from an On-line Spelling and Grammar Checker. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016) Portoroz, Slovenia. http://www.lrec-conf.org/proceedings/lrec2016/index.html Paper
Wooldridge, D. (2011) Gwella Cysill at Ddefnydd Cyfieithwyr: adnabod ymyrraeth gan yr iaith Saesneg mewn testunau Cymraeg. Dissertation
Ellis, N. C., O’Dochartaigh, C., Hicks, W., Morgan, M., & Laporte, N. (2001) Cronfa Electroneg o Gymraeg (CEG) Website
Knight, D. et al (2019) National Corpus of Contemporary Welsh (CorCenCC) http://www.corcencc.cymru/ Website
Deuchar, M. et al (2009) Siarad Corpus http://bangortalk.org.uk/speakers.php?c=siarad Website
Chan, D., and Jones, D.B. (2013) Website
Delyth Prys
Dewi Bryn Jones
September 2019